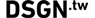

這篇文章是 〈從零開始學 SEO 〉 的第三篇,如果你還沒有看過前面的文章,建議從 〈從零開始學 SEO(一):什麼是搜尋引擎優化(SEO)?〉 開始閱讀,會比較容易了解整個來龍去脈~
設計一個搜尋引擎看的懂的網站
搜索引擎在抓取內容時其實受到很多的限制。就像是隨著不同的裝置與作業系統,我們的網站看起來總不會一樣,對搜索引擎引擎來說更是如此。在本章節中,我們將著力建設(或修改)網頁,使他們的結構容易被搜索引擎(和人類)閱讀。如果你是一個網站的產品負責人,你應該把這個章節分享給你的工程師、信息架構師和設計師,確保架設網站的這些人都理解如何建立對搜尋引擎有利的內容。
建立能夠被索引的內容
如果要被搜尋引擎索引,你的最重要的內容應該都要是 HTML 格式。不管是圖片,Flash 文件,Java 小程式,和其他非文本內容,都很容易在搜尋引擎抓取時被忽視或成為漏網之魚。要確保你顯示你的訪客的單詞和短語是可見的搜索引擎的最簡單方法是將他們以 HTML 的格式呈現。
等等... 你的意思是,難道網站都不要放圖片嗎?
當然不是這樣,針對圖片等內容,我們有幾個優化的重點:
- 提供圖像替代文字。在 GIF,JPG 或 PNG 格式的 HTML 標籤內加上「ALT 屬性」,讓搜尋引擎知道這張圖片是在講什麼。
<img src="/img.jpg" alt="這張圖片的內容"> - 讓你的搜尋頁面具有導航,並且可以被抓取。簡單來說,就是搜尋頁在這樣的結構之下:
首頁 > 搜尋 > 搜尋「關鍵詞」的結果 - 在 Flash 或是 Java 程式裡面加入可以被抓取的文字。但是如果可以不用 Flash 還是盡量不要用啦... 都 2016 年了...
- 如果你的網站有提供影片或是音樂,如果可能的話請在底下加入對白或是文字簡介,讓搜尋引擎可以知道你的網站都提供哪些內容。
如果你是 WordPress 的用戶,基本上 SEO 的結構都 WordPress 已經幫你處理好了,但是上面的 1,3,4 點還是要稍微注意一下。
透過搜尋引擎的眼睛看你的網站
你可以透過 Google 的快取工具,SEO-browser.com 和 MozBar 等工具看到你的網站對搜尋引擎來說是否可見。下面是兩個 Moz 製作的網站範例,你可以參考透過 Google 的快取工具看看這些網站被搜尋引擎收錄時會發生什麼事:
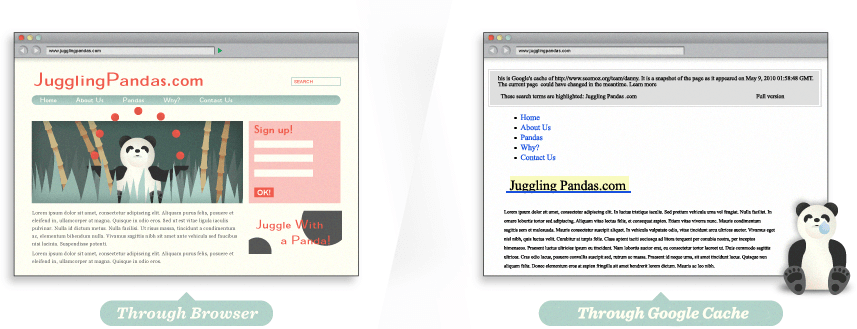
哇!我的網站在 Google 看起來長這樣?
使用 Google 的快取功能,會發現上方的網頁不包含所有我們所看到的豐富的信息。這使得對搜尋引擎來說,很難決定他和關鍵字之間的相關性。
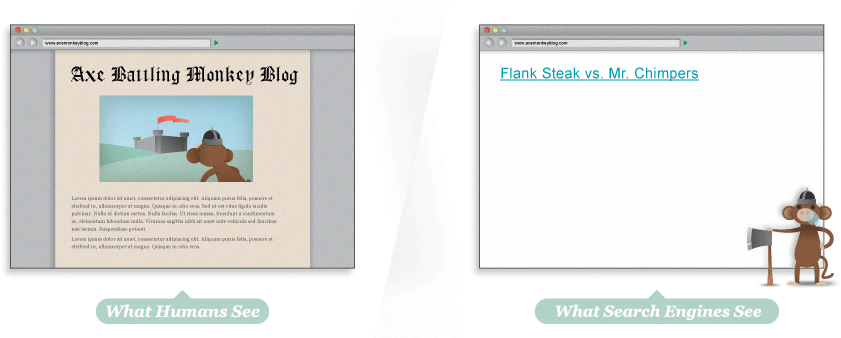
嘿,我的東西都去哪了?
上面這個網站是完全由 Flash 建立的,但可惜的是,這意味著搜索引擎無法索引任何文本內容,甚至是 Flash 裡面的連結。沒有任何 HTML 文本,這個頁面很難在搜尋引擎裡面排上任何名次。
建議在檢查你的網站時,不僅要要確認瀏覽器之間的相容性,也要確認搜尋引擎在快取時,是否可以清楚的讀取你的網站訊息。
可抓取的鏈接結構
正如搜索引擎需要讀取,以列出其龐大的基於關鍵字的索引頁的內容,他們也需要知道這個網站的哪些內容要擺在首位。一個易於抓取的鏈接結構,是讓爬蟲知道如果要到達某個頁面,中間要經過哪些地方。很多網站就是因為沒有做出正確的連結結構,讓搜尋引擎無法訪問,並且阻礙了搜尋引擎替他們的網站建立導航的機會。
下面,Moz 說明了這樣的問題是如何產生的:

以上面的圖示為例,Google 的爬蟲已經達到了頁面 A,並且看到了通往 B 頁面和 E 的連結。但是,即使 C 和 D 可能有很重要的資訊,爬蟲依然沒有辦法達到他們(甚至不知道它們的存在)。這是因為 C 和 D 並沒有直接的連結,如果搜尋引擎看不到,他們就不存在!完整的網頁架構和豐富的內容,良好的關鍵字都是一樣重要的。
哪些連結是永遠無法被抓取的
表單的完成頁
如果要求用戶訪問某些內容之前先填寫表單,那麼搜尋引擎將永遠不會看到這些受保護的頁面。不管是需要輸入密碼、需要登入、或是需要傳送任何資訊,搜尋引擎通常都不會向網頁發送任何資料,所以如果你不希望搜尋引擎爬到某些內容,可以用這個方法擋住。
無法解析的 JavaScript 鏈接
如果使用 JavaScript 的鏈接,你可能會發現,搜尋引擎不會抓取,或給予很少的權重。如果你想要搜尋引擎抓到該內容,最好用 HTML 連結取代 JavaScript 連結。
被 Meta Robot 或是 robots.txt 保護的頁面
Meta Robot 與 robots.txt 式用來保護網站不被惡意攻擊的好方式。但是在使用時需要特別小心,因為很多站長會不小心使用全域式的阻擋,結果把整個爬蟲都擋在外面。
框架或 iFrame
技術上來說,框架和 iframe 鏈接是可以被抓取的,但是對於搜尋引擎而言還是會有結構上的問題。除非你相當了解要如何讓搜尋引擎抓取到框架內的內容,否則最好還是不要使用框架。
機器人不會使用以網站中的搜尋欄
這個和第一點有點相似,但是還是另外抓出來講一下。一些站長認為,如果把搜尋框放在網站裡面,用戶自己就可以找到所有內容了。不幸的是,爬蟲不會快取搜索找到的內容,直到抓取的頁面鏈接到他們。
Flash,Java 和其他外掛程式內的鏈接
上面說的熊貓與猴子的例子即是如此,搜尋引擎是不會記錄 Flash 或是 Java 程式裡面的內容的。如果你的網站完全是使用 Flash 架設的,那麼不僅會讓移動裝置無法讀取,搜尋引擎也很容易查詢不到你的頁面的結果。
裡面放了數百個或數千個連結的網頁
搜尋引擎對每個頁面能抓取的連結數量是有限的。並不是在網頁裡面放一百個連結,就可以這一百個連結同時被搜尋引擎抓取。搜尋引擎自己有一套減少垃圾連結的演算法,如果你的頁面放了這麼多連結,有可能會被當成垃圾頁面。








