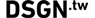

除非你在過去幾個月裡一直藏在岩石上,否則你可能會看到克里斯托弗·黑塞(Christopher Hesse)的 圖像到圖像翻譯的演示 (一個 Tensorflow 港口 pix2pix由Isola等人 )。 如果你錯過了,搜索 edge2cat 並將向您開放一個全新的貓咪人工智能世界。 該模型是針對貓圖像進行訓練的,它可以將手繪的貓翻譯成貓的逼真圖像! 以下是我們個人最喜愛的“邊緣”形象,由Chris的模特生成的貓的翻譯,範圍從準確到可怕:

但是,這樣的模型並不限於創建接管互聯網的奇怪的貓圖像。 他們實際上是非常通用的,可以接受培訓,以進行各種翻譯,包括白天到晚上,建築物的佈局,黑白的顏色等等:
圖片來自 這裡
你甚至可能會想,你想嘗試使用自己的圖像集,看看這個模型會開始抽出什麼樣的瘋狂的東西。 但是,這必須是一個棘手的過程,對吧?
不! 厚皮類動物 已經創建了一個完全可重用且通用的管道,可以為您處理所有的培訓,預處理等,因此您可以直接跳入有趣的部分! 他們利用 本機學習管道模板 (由Pachyderm團隊與Chris合作製作),以顯示部署和管理圖像生成模型(如上圖所示)的容易程度。 可以找到運行可重用管道所需的一切 在這裡Github ,並在下面描述。
Christopher Hesse的圖像到圖像演示使用Tensorflow實現的生成對抗網絡(或GAN)模型 本文 。 Chris的完整Tensorflow可以實現這個模型 在Github上 並包括有關如何執行培訓,測試,圖像預處理,出貨模型等等的文檔。
在這篇文章中,我們將利用Chris的代碼與一個 碼頭圖像 基於 他創造的形象 運行腳本(您也可以在實驗中使用腳本)。
為了部署和管理模型,我們將在可重複使用中執行其培訓,模型導出,預處理和圖像生成 Pachyderm管道 上文提到的。 這將使我們能夠:
- 保持嚴格的歷史記錄,確切地說,什麼樣的模型用於生成哪些數據。
- 在訓練數據或參數化更改時,自動更新在線ML模型。
- 當新型號不執行或將“壞數據”引入到訓練數據集中時,可輕鬆恢復ML模型的其他版本。
我們管道的一般結構如下所示:

氣瓶代表數據“存儲庫”,Pachyderm將在其中進行版本訓練,模型等數據(認為“數據的git”)。 然後,這些數據存儲庫是鏈接數據處理階段的輸入/輸出(由圖中的框表示)。
您可以使用快速本地實驗此管道 本地安裝Pachyderm 。 或者,您可以在任何一個受歡迎的雲提供商中快速啟動一個真正的Pachyderm集群。 看看 Pachyderm文件 有關部署的更多細節。
一旦部署,您將能夠使用Pachyderm的 pachctl CLI工具來創建數據存儲庫並啟動我們的深入學習管道。
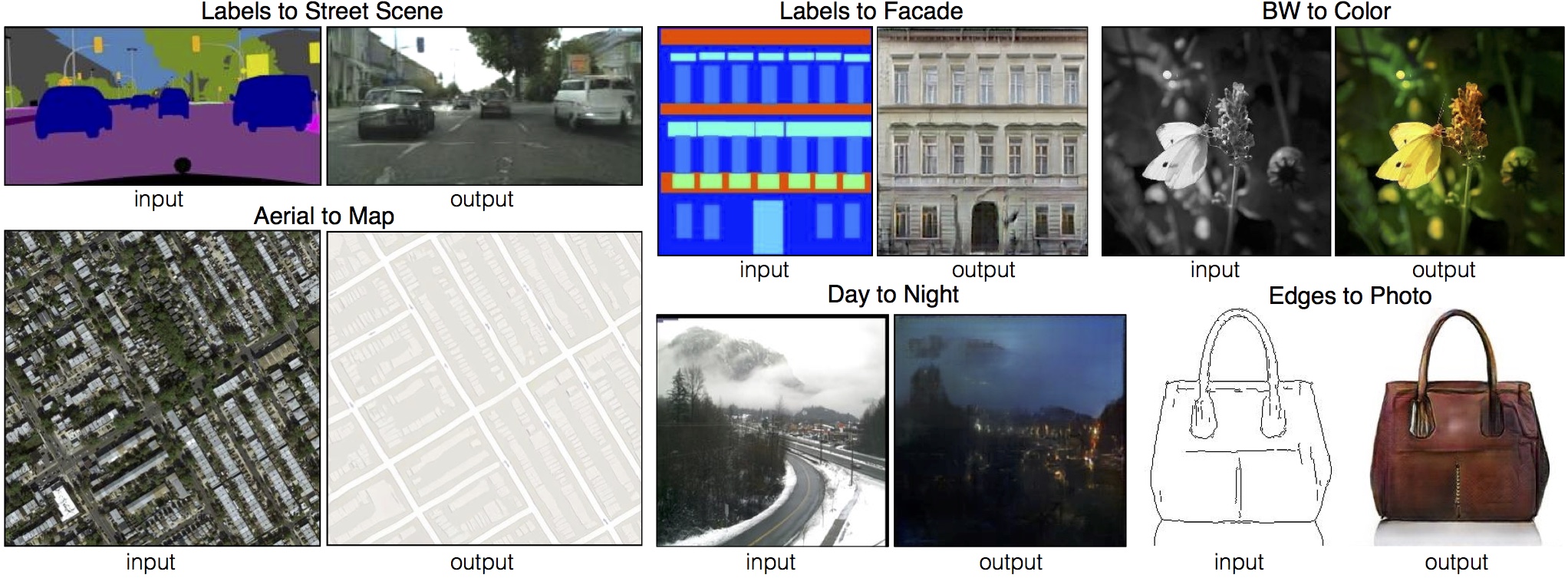
首先,我們來準備培訓和模擬出口階段。 克里斯黑森的 pix2pix.py 腳本包括:
- 一種“火車”模式,我們將使用一組配對圖像來訓練我們的模型(例如與貓配對的標籤或邊緣配對的外牆)。 該訓練將輸出一個表示訓練模型持續狀態的“檢查點”。
- “導出”模式將允許我們創建檢查點模型的導出版本,以在我們的圖像生成中使用。
因此,我們的“模型訓練和出口”階段可以分為產生模型檢查點和出口階段(稱為“模型”)的培訓階段(稱為“檢查點”),產生用於圖像生成的持久模型:
我們可以通過兩個快速步驟部署管道的這一部分:
- 創建初始的“培訓”數據庫
pachctl創建回購培訓。 - 供應Pachyderm與JSON規範,
training_and_export.json告訴Pachyderm:(i)運行克里斯的pix2pix.py在“訓練”模式中的“訓練”存儲庫中的數據的腳本將檢查點輸出到“檢查點”存儲庫,以及(ii)運行pix2pix.py“檢查點”存儲庫中的數據的“導出”模式中的腳本將持久化模型輸出到“模型”存儲庫。 這可以通過運行來完成pachctl create-pipeline -f training_and_export.json。
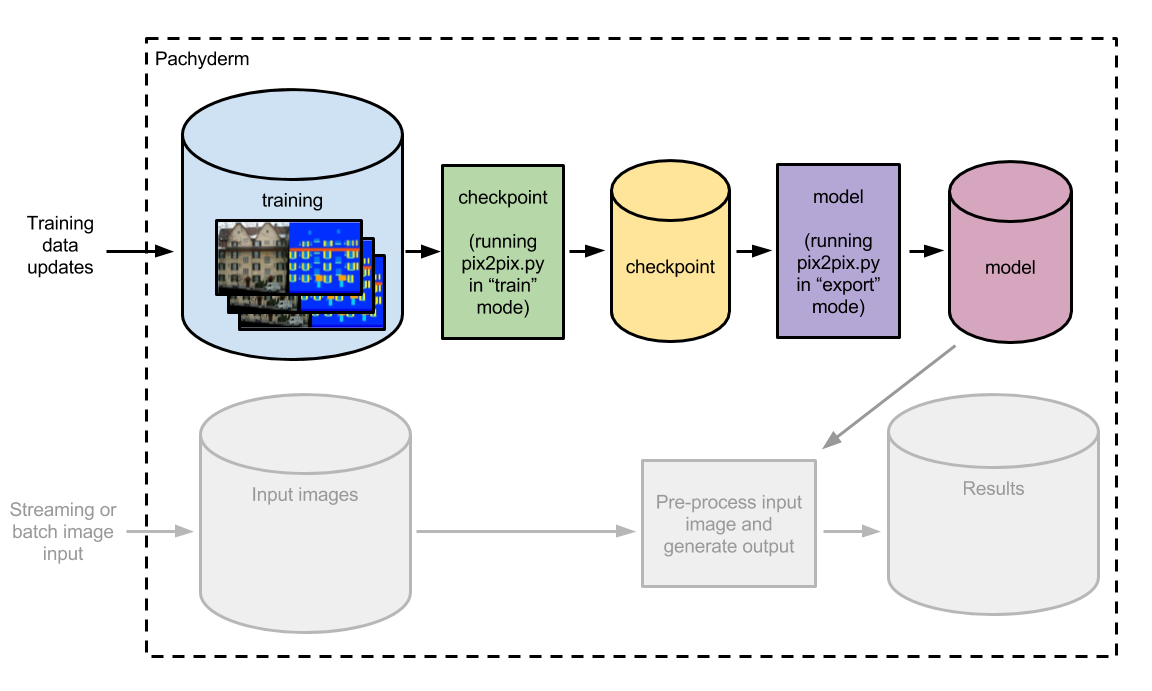
接下來,我們來準備我們的預處理和圖像生成階段。 我們訓練有素的模型將期待具有某些屬性(大小為256 x 256,8位/彩色RGB,非隔行掃描)的PNG圖像數據。 因此,我們需要對我們的圖像進行預處理(特別是調整大小),因為它們正在進入我們的管道中,而Chris已經覆蓋了 process.py 腳本 執行調整大小。
要實際執行我們的圖像到圖像的翻譯,我們需要使用a process_local.py 腳本 。 該腳本將採用我們的預處理圖像和持久化模型作為輸入並輸出生成的翻譯結果:
再次,我們可以通過兩個快速步驟部署管道的這一部分:
- 創建初始的“input_images”數據庫
pachctl create-repo input_images。 - 供應Pachyderm與 另一個JSON規範 ,
預processing_and_generation.json告訴Pachyderm:(i)運行process.py腳本中的“input_images”存儲庫中的數據輸出到“preprocess_images”存儲庫,以及(ii)運行process_local.py模型“存儲庫中的模型和”preprocess_images“存儲庫中的圖像作為輸入。 這可以通過運行來完成pachctl create-pipeline -f pre-processing_and_generation.json。
現在我們已經創建了我們的輸入數據庫(“input_images”和“培訓”),並且告訴Pachyderm所有的處理階段,當我們把數據放入“培訓”和“ input_images“。這只是工作。
克里斯提供了一個準備訓練集的好指南 這裡 。 您可以使用貓圖像,狗圖像,建築物或可能感興趣的任何東西。 有創意,向我們展示你想出來的! 當您準備好訓練和輸入圖像時,您可以使用它們進入Pachyderm pachctl CLI工具或Pachyderm客戶之一(詳細討論) 這裡 )。
有一些靈感,我們運行Pachyderm的管道與Google地圖圖像與衛星圖像配對,以創建一個模型,將Google地圖截圖轉換為類似於衛星圖像的圖像。 一旦我們模擬了我們的模型,我們可以流式傳輸Google地圖截圖,以創建如下翻譯:

準備您的培訓數據集,部署上述模板管道,並確保分享您的結果! 我們迫不及待想看看你想出了什麼瘋狂的東西。
務必:
- 看看這個 GitHub回購 獲得上述參考管道規格以及更詳細的說明。
- 加入 Pachyderm Slack團隊 以獲得幫助實施您的管道。
- 拜訪克里斯 GitHub回購 了解更多關於模型的實現。









